快速链接
最新消息
最新消息
简介
缩进
对齐
花括号
换行
空格
括号
NULL 处理
系统调用返回
声明
宏
头文件包含
注释
汇编
联系方式
下载
文档
在线演示
他们在用!
商业支持
使用 HAProxy 的产品
附加功能
其他解决方案
外部链接
邮件列表归档
10GbE 负载均衡 (已更新)
贡献
已知缺陷
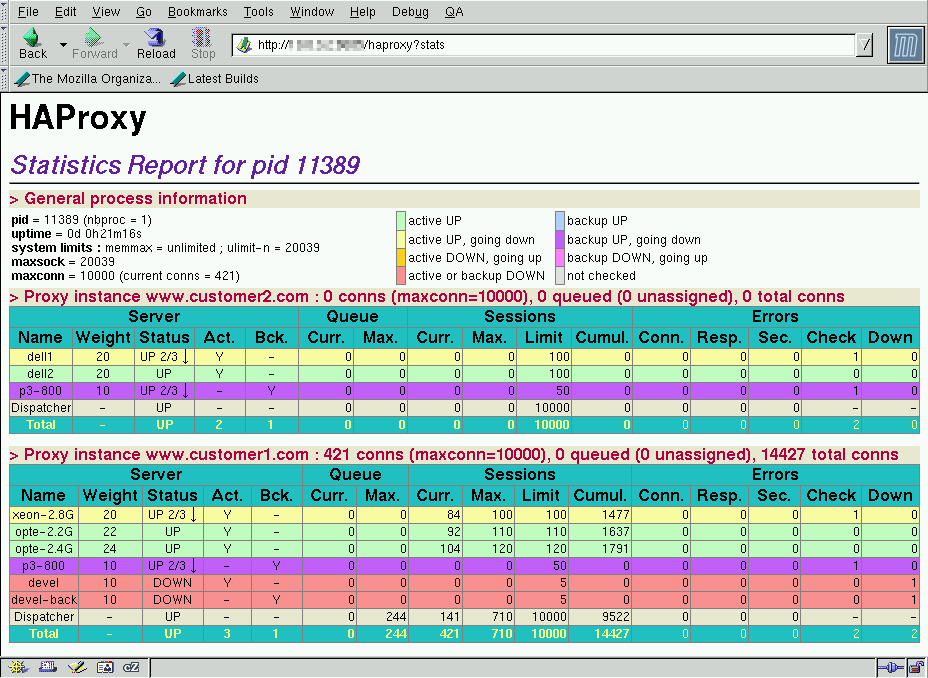
Web 用户界面
HATop:Ncurses 界面
Willy TARREAU
您想捐赠吗?
 在线访客 在线访客


|
|
简介
许多贡献者常常对编码风格问题感到困惑,他们并不总是知道自己做得是否正确,特别是因为编码风格多年来一直在演变。这里解释的不一定是代码中已经应用的,但新代码应尽可能遵循这种风格。编码风格的修复通常在代码被替换时进行。仅仅为了修复编码风格而发送补丁是无用的,它们会被拒绝,除非这些修复是某个补丁系列的一部分,且在进行代码更改前需要这些修复。另外,请避免在同一个补丁中同时进行功能性更改和编码风格修复,这会使代码审查变得更加困难。
在提交补丁之前,一个快速验证的好方法是使用 Linux 内核的 checkpatch.pl 工具进行检查,该工具可在此处下载: 使用以下选项运行它可以放宽检查,以适应 HAProxy 编码风格中相比内核更严格风格所允许的额外自由度:checkpatch.pl --ignore=LEADING_SPACE,CODE_INDENT,DEEP_INDENTATION,ELSE_AFTER_BRACE \
-q --max-line-length=160 --no-tree --no-signoff < patch
|
您可以将其输出作为提示而非严格规则,但通常其输出是准确的,甚至可能发现一些真正的错误。
修改文件时,您必须接受该文件许可证的条款,该许可证在文件顶部有说明,或者在LICENSE文件中有解释,或者如果未声明,则默认为:LGPL版本 2.1 或更高版本(对于include目录中的文件),以及GPL版本 2 或更高版本(对于所有其他文件)。
添加新文件时,您必须在文件顶部添加一个版权声明,包含您的真实姓名、电子邮件地址和许可证提醒。使用不兼容或限制性过强的许可证的贡献可能会被拒绝。如有疑问,请遵循上述针对现有文件的原则。
本文档中的制表符将表示为一系列 8 个空格,以便在任何地方都能相同地显示。
1) 缩进和对齐
1.1) 缩进
缩进和对齐是人们经常混淆的两个完全不同的概念。缩进用于标记代码中的一个子级别。子级别意味着一个代码块在另一个代码块(例如:一个函数或一个条件)的上下文中执行。
main(int argc, char **argv)
{
int i;
if (argc < 2)
exit(1);
} |
在上面的例子中,代码属于 main() 函数,而 exit() 调用属于 if 语句。缩进使用制表符(\t,ASCII 9),这允许任何开发者配置他们偏好的编辑器来使用自己的制表符大小,并且仍然能正确地缩进文本。每个子级别只使用一个制表符。制表符只能出现在一行的开头或另一个制表符之后。在某些文本之后放置制表符是非法的,因为它会对不同的用户以不同的方式搞乱显示(尤其是在用于对齐注释或 #define 之后的值时)。如果你想在某些文本后放置制表符,那么你做错了,你需要的是对齐(见下文)。
请注意,有些地方的代码过去没有正确缩进。为了正确查看,您可能需要将制表符大小设置为 8 个字符。
1.2) 对齐
对齐用于以一种使事物更容易组合在一起的方式续行。根据定义,对齐是基于字符的,所以它使用空格。制表符在这里行不通,因为一个制表符在所有显示器上不会有相同数量的字符。例如,函数声明中的参数可以使用对齐空格分成多行:
int http_header_match2(const char *hdr, const char *end,
const char *name, int len)
{
...
}
|
在这个例子中,“const char *name”部分与它所属的组(函数参数列表)的第一个字符对齐。把它放在这里,很明显它是函数的参数之一。用这种方式处理多行很容易。这在长条件语句中也很常见:
if ((len < eol - sol) &&
(sol[len] == ':') &&
(strncasecmp(sol, name, len) == 0)) {
ctx->del = len;
}
|
如果我们再次使用上面的例子,用“[-Tabs-]”标记制表符,用“#”标记空格,我们会得到这个:
[-Tabs-]if ((len < eol - sol) &&
[-Tabs-]####(sol[len] == ':') &&
[-Tabs-]####(strncasecmp(sol, name, len) == 0)) {
[-Tabs-][-Tabs-]ctx->del = len;
[-Tabs-]}
|
值得注意的是,一些编辑器倾向于混淆缩进和对齐。Emacs 在这方面的糟糕表现是众所周知的,并且几乎是所有对齐混乱的罪魁祸首。原因是 Emacs 只计算空格,试图用制表符填充尽可能多的空间,然后用空格补全。一旦你知道了这一点,你只需要小心一点,因为对齐用得不多,所以通常情况下,当这种情况发生时,只需将最后一个制表符替换为 8 个空格即可。
在有代码块或左花括号的地方都应该使用缩进。不可能有两个连续的右花括号在同一列上,这意味着最里面的那个没有被缩进。
正确: main(int argc, char **argv)
{
if (argc > 1) {
printf("Hello\n");
}
exit(0);
}
|
错误: main(int argc, char **argv)
{
if (argc > 1) {
printf("Hello\n");
}
exit(0);
}
|
一个特例适用于 switch/case 语句。由于我的编辑器设置,我习惯于将“case”与“switch”对齐,并觉得这在某种程度上是合乎逻辑的,因为每个“case”语句都打开了一个属于“switch”语句的子级别。但是将“case”缩进在“switch”之后也是可以接受的。然而,在任何情况下,跟在“case”语句后面的内容都必须缩进,无论它是否包含花括号。
switch (*arg) {
case 'A': {
int i;
for (i = 0; i < 10; i++)
printf("Please stop pressing 'A'!\n");
break;
}
case 'B':
printf("You pressed 'B'\n");
break;
case 'C':
case 'D':
printf("You pressed 'C' or 'D'\n");
break;
default:
printf("I don't know what you pressed\n");
}
|
2) 花括号
花括号用于界定多指令块。通常,我们倾向于避免在单指令块周围使用花括号,因为这样可以减少行数。
正确:
错误: if (argc >= 2) {
exit(0);
}
|
但这并非严格规定,具体取决于上下文。有时,单指令块也会用花括号括起来,因为这样可以使代码更对称或更易读。例如:
if (argc < 2) {
printf("Missing argument\n");
exit(1);
} else {
exit(0);
}
|
声明函数时总是需要花括号。函数的左花括号必须放在下一行的开头。
正确: int main(int argc, char **argv)
{
exit(0);
}
|
错误: int main(int argc, char **argv) {
exit(0);
}
|
请注意,大部分代码仍然不符合此规则,因为让所有作者适应这个现在更受欢迎的、更通用的标准花了很多年时间,这个标准可以避免当函数声明被分成多行时产生的视觉混淆。
正确: int foo(const char *hdr, const char *end,
const char *name, const char *err,
int len)
{
int i;
|
错误: int foo(const char *hdr, const char *end,
const char *name, const char *err,
int len) {
int i;
|
在以后可能会对代码产生歧义的地方,应始终使用花括号。最常见的例子是嵌套的“if”语句,其中“else”稍后可能会被添加到错误的位置,从而破坏代码,但这种情况也发生在注释或函数调用中的长参数中。通常,如果一个代码块超过一行,就应该使用花括号。
等待受害者的危险代码: if (argc < 2)
/* ret must not be negative here */
if (ret < 0)
return -1;
|
错误的修改: if (argc < 2)
/* ret must not be negative here */
if (ret < 0)
return -1;
else
return 0;
|
它会执行这个,而不是你眼睛看起来的样子: if (argc < 2)
/* ret must not be negative here */
if (ret < 0)
return -1;
else
return 0;
|
正确: if (argc < 2) {
/* ret must not be negative here */
if (ret < 0)
return -1;
}
else
return 0;
|
类似的危险示例: if (ret < 0)
/* ret must not be negative here */
complain();
init();
|
为了消除烦人的消息而进行的错误修改: if (ret < 0)
/* ret must not be negative here */
//complain();
init();
|
... 实际上意味着:
3) 换行
换行没有严格的规则。有些文件试图遵守 80 列的限制,但考虑到不同的人使用不同的制表符大小,这没有太大意义。而且,代码行数少有时更易读,因为它在屏幕上占用的面积更小(因为每增加一行都会增加其制表符和空格)。规则是与其它行的平均长度保持一致。如果你正在一个适合 80 列的文件中工作,请尽量记住这个目标。如果你在一个有 120 字符行的函数中,就没有理由增加许多短行,所以你可以写更长的行。
通常,开始一个新块应该另起一行。同样,应避免在同一行上写多条指令。但有些结构在完美对齐时更易读。
在以下结构中,复制粘贴错误更容易被发现:
if (omult % idiv == 0) { omult /= idiv; idiv = 1; }
if (idiv % omult == 0) { idiv /= omult; omult = 1; }
if (imult % odiv == 0) { imult /= odiv; odiv = 1; }
if (odiv % imult == 0) { odiv /= imult; imult = 1; }
|
而不是在这个结构中: if (omult % idiv == 0) {
omult /= idiv;
idiv = 1;
}
if (idiv % omult == 0) {
idiv /= omult;
omult = 1;
}
if (imult % odiv == 0) {
imult /= odiv;
odiv = 1;
}
if (odiv % imult == 0) {
odiv /= imult;
imult = 1;
}
|
重要的是不要混合风格。例如,只要大多数“case”语句都像下面这样短,那么有很多单行的“case”语句是完全没有问题的。
switch (*arg) {
case 'A': ret = 1; break;
case 'B': ret = 2; break;
case 'C': ret = 4; break;
case 'D': ret = 8; break;
default : ret = 0; break;
}
|
否则,最好将“case”语句单独放在一行,如关于对齐的 1.2 节中的示例。在任何情况下,避免在同一行上堆叠多个控制语句,这样就永远不需要一次性增加两个制表符级别。
正确: switch (*arg) {
case 'A':
if (ret < 0)
ret = 1;
break;
default : ret = 0; break;
}
|
错误: switch (*arg) {
case 'A': if (ret < 0)
ret = 1;
break;
default : ret = 0; break;
}
|
正确: if (argc < 2)
if (ret < 0)
return -1;
|
或正确: if (argc < 2)
if (ret < 0) return -1;
|
但错误: if (argc < 2) if (ret < 0) return -1;
|
当复杂的条件或表达式被分成多行时,请确保对齐完全适当,并将所有主要运算符分组到同一侧(你可以自由选择哪一侧,只要它不因每个块而改变)。将二元运算符放在右侧是首选,因为它不会干扰对齐,但不同的人有不同的偏好。
正确: if ((txn->flags & TX_NOT_FIRST) &&
((req->flags & BF_FULL) ||
req->r < req->lr ||
req->r > req->data + req->size - global.tune.maxrewrite)) {
return 0;
}
|
正确: if ((txn->flags & TX_NOT_FIRST)
&& ((req->flags & BF_FULL)
|| req->r < req->lr
|| req->r > req->data + req->size - global.tune.maxrewrite)) {
return 0;
}
|
错误: if ((txn->flags & TX_NOT_FIRST) &&
((req->flags & BF_FULL) ||
req->r < req->lr
|| req->r > req->data + req->size - global.tune.maxrewrite)) {
return 0;
}
|
如果这样能使结果更易读,括号甚至可以单独放在一行,以便与开括号对齐。请注意,通常不需要这样做,因为这样的代码会过于复杂,难以深入理解。
“else”语句既可以与闭合的“if”花括号合并,也可以单独占一行。后者是首选,但它会给每个控制块增加一行,这在短代码块中很烦人。然而,如果“else”后面跟着一个“if”,那么它就应该单独占一行,并且“if/else”块的其余部分必须遵循相同的风格。
正确: if (a < b) {
return a;
}
else {
return b;
}
|
正确: if (a < b) {
return a;
} else {
return b;
}
|
正确: if (a < b) {
return a;
}
else if (a != b) {
return b;
}
else {
return 0;
}
|
错误: if (a < b) {
return a;
} else if (a != b) {
return b;
} else {
return 0;
}
|
错误: if (a < b) {
return a;
}
else if (a != b) {
return b;
} else {
return 0;
}
|
4) 空格
正确地使用空格对代码非常重要。当你在凌晨 3 点需要找出一个 bug 时,你需要代码清晰明了。当你希望其他人审查你的代码时,你希望它清晰,不希望他们在试图弄清楚你做了什么时变得紧张。
总是在所有二元或三元运算符、逗号周围放置空格,以及在分号和如果行继续的左花括号后放置空格。
正确: int ret = 0;
/* if (x >> 4) { x >>= 4; ret += 4; } */
ret += (x >> 4) ? (x >>= 4, 4) : 0;
val = ret + ((0xFFFFAA50U >> (x << 1)) & 3) + 1;
|
错误: int ret=0;
/* if (x>>4) {x>>=4;ret+=4;} */
ret+=(x>>4)?(x>>=4,4):0;
val=ret+((0xFFFFAA50U>>(x<<1))&3)+1;
|
绝不在一元运算符(&, *, -, !, ~, ++, --)或类型转换之后放置空格,因为它们可能会与它们的二元对应物混淆,也不要在逗号或分号之前放置空格。
正确: bit = !!(~len++ ^ -(unsigned char)*x);
|
错误: bit = ! ! (~len++ ^ - (unsigned char) * x) ;
|
注意,“sizeof”是一个一元运算符,有时被认为是语言关键字,但它绝不是一个函数。它不需要括号,所以在没有括号的情况下,有时后面会跟空格,有时不会。只要写的东西没有歧义,大多数人并不太在意。
开启一个块的左花括号前必须有一个空格,除非该花括号位于第一列。
正确:
错误:
不要在括号内添加不必要的空格,它们只会让代码更难读。
正确: if (x < 4 && (!y || !z))
break;
|
错误: if ( x < 4 && ( !y || !z ) )
break;
|
语言关键字后面必须都跟一个空格。这适用于控制语句(do, for, while, if, else, return, switch, case),也适用于类型(int, char, unsigned)。作为例外,类型转换中的最后一个类型在右括号前不加空格。“switch”结构中的“default”语句通常只跟着冒号。然而,“case”或“default”语句后的冒号必须跟一个空格。
正确: if (nbargs < 2) {
printf("Missing arg at %c\n", *(char *)ptr);
for (i = 0; i < 10; i++) beep();
return 0;
}
switch (*arg) {
|
错误: if(nbargs < 2){
printf("Missing arg at %c\n", *(char*)ptr);
for(i = 0; i < 10; i++)beep();
return 0;
}
switch(*arg) {
|
函数调用是不同的,左括号总是紧跟函数名,没有任何空格。但逗号后面仍然需要空格。
正确: if (!init(argc, argv))
exit(1);
|
错误: if (!init (argc,argv))
exit(1);
|
5) 过多或过少的括号
有时在一些公式中括号太多,有时又太少。对此有几条经验法则。第一条是尊重编译器的建议。如果它发出警告并要求添加更多括号以避免混淆,至少为了消除警告,请遵循建议。例如,下面的代码由于其对齐方式而相当模糊。
if (var1 < 2 || var2 < 2 &&
var3 != var4) {
/* fail */
return -3;
}
|
请注意,此代码执行的是: if (var1 < 2 || (var2 < 2 && var3 != var4)) {
/* fail */
return -3;
}
|
但也许作者的意思是: if ((var1 < 2 || var2 < 2) && var3 != var4) {
/* fail */
return -3;
}
|
使用括号的第二个规则是,人们并不总是很清楚运算符的优先级。通常,他们对同一类别的运算符(例如:布尔、整数、位操作、赋值)没有问题,但一旦这些运算符混合使用,就会给他们带来各种问题。在这种情况下,使用括号来避免错误是明智的。一个常见的错误涉及位移运算符,因为它们被用来替代乘法和除法,但优先级不同。
表达式:
变成:
这是错误的,因为它等同于:
而期望的结果是:
通常,写基于比较的布尔表达式而不加任何括号是可以的。但除此之外,整数表达式和赋值应该被保护起来。例如,下面的表达式中有一个错误,应该安全地重写。
错误: if (var1 > 2 && var1 < 10 ||
var1 > 2 + 256 && var2 < 10 + 256 ||
var1 > 2 + 1 << 16 && var2 < 10 + 2 << 16)
return 1;
|
正确(根据个人喜好可以去掉一些括号): if ((var1 > 2 && var1 < 10) ||
(var1 > (2 + 256) && var2 < (10 + 256)) ||
(var1 > (2 + (1 << 16)) && var2 < (10 + (1 << 16))))
return 1;
|
“return”语句不是一个函数,所以它不接受参数。它是一个控制语句,后面跟着要返回的表达式。它后面不需要加括号。
错误: int ret0()
{
return(0);
}
|
正确:
括号也出现在类型转换中。应尽可能避免类型转换,尤其是在涉及指针类型时。转换指针会禁用编译器的类型检查,是导致你用错误大小的数据做错误事情的最佳方式。如果你需要操作多种数据类型,可以使用联合(union)。如果联合确实不方便,而类型转换更容易,那么尽量将它们隔离,例如在初始化函数参数时或在另一个函数中。不这样做会带来巨大的风险,即在没有任何通知的情况下使用错误的指针,这在复制粘贴时尤其如此。
错误: void *check_private_data(void *arg1, void *arg2)
{
char *area;
if (*(int *)arg1 > 1000)
return NULL;
if (memcmp(*(const char *)arg2, "send(", 5) != 0))
return NULL;
area = malloc(*(int *)arg1);
if (!area)
return NULL;
memcpy(area, *(const char *)arg2 + 5, *(int *)arg1);
return area;
}
|
正确: void *check_private_data(void *arg1, void *arg2)
{
char *area;
int len = *(int *)arg1;
const char *msg = arg2;
if (len > 1000)
return NULL;
if (memcmp(msg, "send(", 5) != 0))
return NULL;
area = malloc(len);
if (!area)
return NULL;
memcpy(area, msg + 5, len);
return area;
}
|
6) 与零或 NULL 的模糊比较
在 C 语言中,'0' 没有类型,或者它具有被赋值变量的类型。将变量或返回值与零进行比较,意味着与该变量类型的零表示进行比较。对于布尔值,零是 false。对于指针,零是 NULL。通常,为了简化,使用 '!' 一元运算符与零进行比较是可以的,因为它比一个普通的 '0' 更短,也更容易记住或理解。由于 '!' 运算符读作“非”("not"),当其后的内容作为布尔值有意义时,它有助于更快地阅读代码,并且通常比与零的比较更合适,后者会在不希望出现的地方引入等号。
例如: if (!isdigit(*c) && !isspace(*c))
break;
|
比这个更容易理解: if (isdigit(*c) == 0 && isspace(*c) == 0)
break;
|
对于一个字符,这个“非”运算符可以被记为“没有剩余字符”,并且不与零比较意味着被测试实体的存在,因此下面这个简单的 strcpy() 实现会在复制完最后一个零后自动停止。
void my_strcpy(char *d, const char *s)
{
while ((*d++ = *s++));
}
|
注意双括号,以避免编译器告诉我们它看起来像一个相等性测试。
对于字符串或更一般的任何指针,这个测试可以理解为存在性测试或有效性测试,因为唯一不能通过相等性验证的指针是 NULL 指针。
area = malloc(1000);
if (!area)
return -1;
|
然而,有时它会迷惑读者。例如,strcmp() 正是这样一个函数,其返回值可能会让人产生相反的想法,因为它的名字可以被理解为“如果字符串比较...”。因此,强烈建议在这种情况下进行与零的显式比较,考虑到比较运算符与想要比较字符串的运算符相同,这样做是有道理的(请注意,当前的配置解析器在这方面有很多欠缺)。
strcmp(a, b) == 0 <=> a == b
strcmp(a, b) != 0 <=> a != b
strcmp(a, b) < 0 <=> a < b
strcmp(a, b) > 0 <=> a > b
避免这样写: if (strcmp(arg, "test"))
printf("this is not a test\n");
if (!strcmp(arg, "test"))
printf("this is a test\n");
|
倾向于这样写: if (strcmp(arg, "test") != 0)
printf("this is not a test\n");
if (strcmp(arg, "test") == 0)
printf("this is a test\n");
|
7) 系统调用返回
这不直接是编码风格的问题,更多是坏习惯。检查系统调用的正确返回值非常重要。表示错误的正确返回码在其手册页(man page)中有描述。没有理由考虑比所指示的更宽的范围。例如,常见到这样的写法:
if ((fd = open(file, O_RDONLY)) < 0)
return -1;
|
这是错误的。手册页说,如果发生错误,返回 -1。它并没有暗示任何其他负值都是错误。现有代码中可能还留有一些这样的问题。它们是 bug,我们接受对其的修复,尽管它们目前是无害的,因为目前为止 open() 还没有返回负值的已知情况。
8) 声明新的类型、名称和值
请避免使用“typedef”来声明新类型,它们只会混淆代码。读者永远不知道他是在操作一个标量类型还是一个结构体。例如,下面的代码为什么会构建失败并不明显:
int delay_expired(timer_t exp, timer_us_t now)
{
return now >= exp;
}
|
而类型在另一个文件中是这样声明的: typedef unsigned int timer_t;
typedef struct timeval timer_us_t;
|
这行不通,因为我们正在比较一个标量和一个结构体,这没有意义。如果没有 typedef,这个函数本可以这样写,没有任何歧义,也不会失败:
int delay_expired(unsigned int exp, struct timeval *now)
{
return now >= exp->tv_sec;
}
|
声明特殊值可以使用枚举(enums)。枚举是一种定义相互关联的结构化整数值的方法。它们非常适合状态机。第一个元素总是被赋值为零,但不是每个人都知道这一点,特别是那些整天使用多种语言的人。因此,建议即使第一个值是零,也要显式地强制赋值。如果计划将来会添加新元素,最后一个元素后面应该跟一个逗号,这将使以后的补丁更短。相反,如果最后一个元素是为了获取可能值的数量而放置的,它后面不能有逗号,并且前面必须有注释。
enum {
first = 0,
second,
third,
fourth,
};
|
enum {
first = 0,
second,
third,
fourth,
/* nbvalues must always be placed last */
nbvalues
};
|
结构体名称应该足够短,以免搞乱函数声明,并且足够明确以避免混淆(这才是最重要的)。
错误: struct request_args { /* arguments on the query string */
char *name;
char *value;
struct request_args *next;
};
|
正确: struct qs_args { /* arguments on the query string */
char *name;
char *value;
struct qs_args *next;
}
|
在声明新函数或结构体时,请不要使用驼峰命名法(CamelCase),这是一种在单个单词中混合使用大小写的风格。当单词由缩写词组成时,它会引起很多混淆,因为很难遵守一个规则。例如,一个设计用于为 TCP/IP 连接生成 ISN(初始序列号)的函数可能被命名为:
- generateTcpipIsn()
- generateTcpIpIsn()
- generateTcpIpISN()
- generateTCPIPISN()
- 等等...
没有哪个是绝对正确或错误的,这些只是个人偏好,可能会在代码中发生变化。相反,请使用下划线来分隔单词。单词首选小写,但如果缩写词大写也不是什么大问题。这种方法的真正优势在于,即使是短名称,它也能创建明确的层次。
有效示例:
- generate_tcpip_isn()
- generate_tcp_ip_isn()
- generate_TCPIP_ISN()
- generate_TCP_IP_ISN()
当函数命名涉及 3 个参数时,另一个例子很容易理解:
错误(命名冲突): /* returns A + B * C */
int mulABC(int a, int b, int c)
{
return a + b * c;
}
/* returns (A + B) * C */
int mulABC(int a, int b, int c)
{
return (a + b) * c;
}
|
正确(命名明确): /* returns A + B * C */
int mul_a_bc(int a, int b, int c)
{
return a + b * c;
}
/* returns (A + B) * C */
int mul_ab_c(int a, int b, int c)
{
return (a + b) * c;
}
|
无论何时操作指针,尽量将它们声明为“const”,因为这可以避免许多意外的误用,并且只有在存在真正风险时才会发出警告。在下面的例子中,只有在第一个声明中才可以用 const 字符串调用 my_strcpy()。请注意,那些忽略“const”的人通常也是那些大量使用类型转换并且在使用 strtok() 时抱怨段错误的人!
正确: void my_strcpy(char *d, const char *s)
{
while ((*d++ = *s++));
}
void say_hello(char *dest)
{
my_strcpy(dest, "hello\n");
}
|
错误: void my_strcpy(char *d, char *s)
{
while ((*d++ = *s++));
}
void say_hello(char *dest)
{
my_strcpy(dest, "hello\n");
}
|
9) 正确使用宏
宏在其作者未曾想到的使用方式下做出错误行为是很常见的。因此,宏必须始终只用大写字母命名。这是在使用它们时引起开发者注意的唯一方法,以便他可以仔细检查是否存在风险。首先,宏绝不能以分号结尾,否则它们偶尔会关闭错误的块。例如,由于双分号,以下代码将在“else”之前导致构建错误。
错误:#define WARN printf("warning\n");
...
if (a < 0)
WARN;
else
a--;
|
正确: #define WARN printf("warning\n")
|
如果需要多个指令,那么使用一个 do { } while (0) 块,这是唯一一个*完全*符合单条指令语义的结构。
#define WARN do { printf("warning\n"); log("warning\n"); } while (0)
...
if (a < 0)
WARN;
else
a--;
|
其次,不要在宏中放置未受保护的控制语句,它们肯定会导致 bug。
错误: #define WARN if (verbose) printf("warning\n")
...
if (a < 0)
WARN;
else
a--;
|
这等同于下面这种不希望的形式: if (a < 0)
if (verbose)
printf("warning\n");
else
a--;
|
正确的做法是: #define WARN do { if (verbose) printf("warning\n"); } while (0)
...
if (a < 0)
WARN;
else
a--;
|
这等同于: if (a < 0)
do { if (verbose) printf("warning\n"); } while (0);
else
a--;
|
宏参数必须始终用括号括起来,并且除非明确说明,否则绝不能在同一个宏中重复出现。此外,宏的定义中,运算符两边必须有括号。MIN/MAX 宏是多种误用的一个很常见的例子,但这种情况在使用位掩码时就已经出现了。大多数时候,如有任何疑问,请尝试使用内联函数。
错误: #define MIN(a, b) a < b ? a : b
/* returns 2 * min(a,b) + 1 */
int double_min_p1(int a, int b)
{
return 2 * MIN(a, b) + 1;
}
|
这将导致: int double_min_p1(int a, int b)
{
return 2 * a < b ? a : b + 1;
}
|
这等同于: int double_min_p1(int a, int b)
{
return (2 * a) < b ? a : (b + 1);
}
|
首先要修复的是用括号将宏定义括起来,以避免这个错误:
#define MIN(a, b) (a < b ? a : b)
|
但这仍然不够,如此例所示: /* compares either a or b with c */
int min_ab_c(int a, int b, int c)
{
return MIN(a ? a : b, c);
}
|
这等同于: int min_ab_c(int a, int b, int c)
{
return (a ? a : b < c ? a ? a : b : c);
}
|
由于优先级问题,这又意味着完全不同的事情: int min_ab_c(int a, int b, int c)
{
return (a ? a : ((b < c) ? (a ? a : b) : c));
}
|
这可以通过在宏中用括号括住*每个*参数来修复。 #define MIN(a, b) ((a) < (b) ? (a) : (b))
|
但这仍然不够,如此例所示: int min_ap1_b(int a, int b)
{
return MIN(++a, b);
}
|
这等同于: int min_ap1_b(int a, int b)
{
return ((++a) < (b) ? (++a) : (b));
}
|
这仍然是错误的,因为如果“a”小于“b”,它会被递增两次。修复这个问题的唯一方法是使用复合语句,并将每个参数只赋值一次给相同类型的局部变量。
#define MIN(a, b) ({ typeof(a) __a = (a); typeof(b) __b = (b); \
((__a) < (__b) ? (__a) : (__b)); \
})
|
此时,如果只使用一种类型,使用 static inline 函数会更清晰。
static inline int min(int a, int b)
{
return a < b ? a : b;
}
|
10) 头文件包含
头文件包含应尽可能按字母顺序分组排列:
- libc 标准头文件(那些没有任何路径组件的)
- 或多或少与系统相关的头文件(
sys/*, netinet/*, ...) - 来自本地“
common”子目录的头文件 - 来自本地“
types”子目录的头文件 - 来自本地“
proto”子目录的头文件
每个部分仅通过一个空行与其他部分在视觉上分隔开。根据开发者的偏好,上面前两个部分可以合并为一个部分。请不要从其他文件复制粘贴 include 语句。包含过多的头文件会显著增加构建时间,并使以后查找哪些是必需的变得困难。只包含你需要的内容,并尽可能按字母顺序排列,这样当缺少某些东西时,就很容易知道在哪里查找和添加它。
所有文件都应包含 <common/config.h>,因为这是准备构建选项的地方。
头文件根据其提供的内容被分为两个目录(“types”和“proto”)。类型、结构体、枚举和 #defines 必须放在“types”目录中。函数原型和内联函数必须放在“proto”目录中。这种分离是因为内联函数会交叉引用其他文件中的类型,如果函数和类型在同一个地方声明,会导致先有鸡还是先有蛋的问题。
所有不依赖任何东西的头文件目前都放在“common”子目录中,但放在“proto”目录中也同样合适。将来“common”目录可能会消失。
头文件必须使用常见的 #ifndef/#define/#endif 技巧,并使用从头文件及其位置派生的标签来防止重复包含。
11) 注释
注释最好使用标准的 'C' 形式,即“/* */”。C++ 形式的“//”对于非常短的注释(例如:一两个词)是可以容忍的,但应尽可能避免。多行注释的制作方法是,每个中间行都以一个星号开头,并与第一个星号对齐,如此例所示:
/*
* This is a multi-line
* comment.
*/
|
如果多行代码需要简短的注释,请尝试将它们对齐,以便可以形成多行句子。这种情况很少需要,只适用于真正复杂的结构。
不要在注释中说明你在做什么,而是解释你为什么这么做,如果这看起来不明显的话。同时,*务必*在函数顶部指明它们接受什么和不接受什么。例如,strcpy() 只接受至少与输入缓冲区一样大的输出缓冲区,并且不支持任何 NULL 指针。如果调用者知道这一点,那就没有问题。
错误的注释用法: int flsnz8(unsigned int x)
{
int ret = 0; /* initialize ret */
if (x >> 4) { x >>= 4; ret += 4; } /* add 4 to ret if needed */
return ret + ((0xFFFFAA50U >> (x << 1)) & 3) + 1; /* add ??? */
}
...
bit = ~len + (skip << 3) + 9; /* update bit */
|
正确的注释用法: /* This function returns the position of the highest bit set in the lowest
* byte of <x>, between 0 and 7. It only works if <x> is non-null. It uses
* a 32-bit value as a lookup table to return one of 4 values for the
* highest 16 possible 4-bit values.
*/
int flsnz8(unsigned int x)
{
int ret = 0;
if (x >> 4) { x >>= 4; ret += 4; }
return ret + ((0xFFFFAA50U >> (x << 1)) & 3) + 1;
}
...
bit = ~len + (skip << 3) + 9; /* (skip << 3) + (8 - len), saves 1 cycle */
|
12) 汇编的使用
在许多项目中,不欢迎使用汇编代码。在 haproxy 中使用汇编没有问题,前提是:
- a) 为未覆盖的体系结构提供备用的 C 语言形式
- b) 代码足够小且注释足够好,以便于维护
重要的是要注意不同编译器版本之间的各种不兼容性,例如关于输出和被破坏寄存器(clobbered registers)方面。网上有许多关于这个主题的文档。无论如何,如果你在摆弄汇编,你可能已经知道了。
示例: /* gcc does not know when it can safely divide 64 bits by 32 bits. Use this
* function when you know for sure that the result fits in 32 bits, because
* it is optimal on x86 and on 64bit processors.
*/
static inline unsigned int div64_32(unsigned long long o1, unsigned int o2)
{
unsigned int result;
#ifdef __i386__
asm("divl %2"
: "=a" (result)
: "A"(o1), "rm"(o2));
#else
result = o1 / o2;
#endif
return result;
}
|
如有任何问题或意见,请随时通过以下方式与我联系:
有些人经常问是否可以发送捐款,所以我为此设立了一个 Paypal 账户。如果您想捐款,请点击这里。
|
|