快速链接
最新消息描述
主要特性
支持的平台
性能
可靠性
安全性
下载
文档
在线演示
他们在用!
商业支持
附加功能
其他解决方案
联系方式
外部链接
邮件列表归档
Willy TARREAU
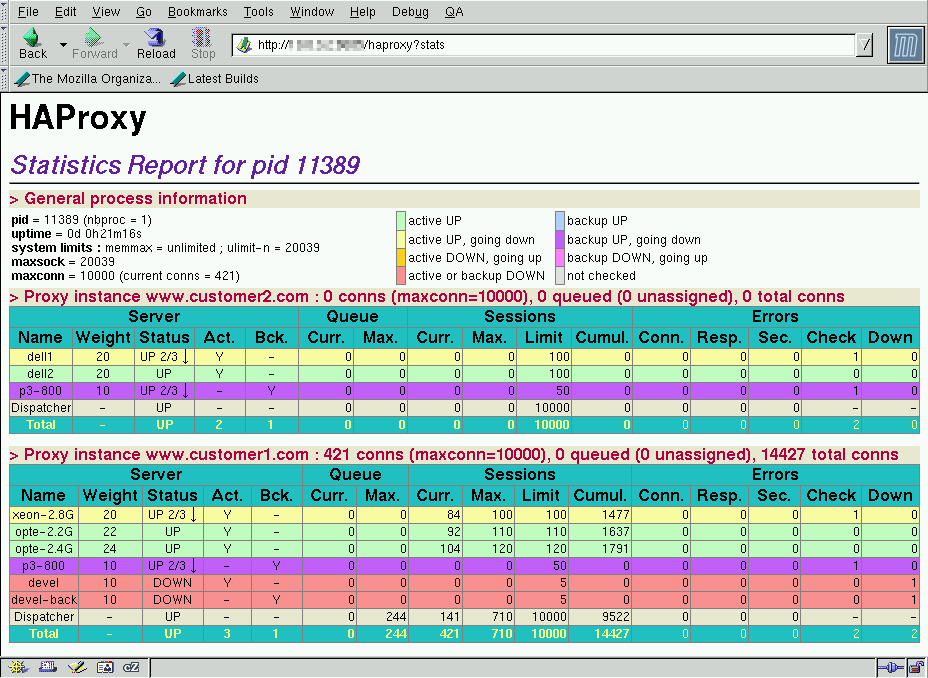
2009/08/23 - 1.4-dev2 版本快速测试:突破 10 万 HTTP 请求/秒大关
引言
- 这是我搬家后的第一次测试。我想快速地将机器连接起来,看看我对 1.4 版本所做的工作是否朝着正确的方向发展,最重要的是,没有导致性能下降。下面的结论证实了这一点。每秒处理 108000 个 HTTP 请求的新纪录被打破,同时每秒转发 40000 个 HTTP 请求的新纪录也被打破。
第一个测试只接受新连接,读取请求,解析它,检查一个 ACL,发送一个重定向并关闭连接。在纯 TCP 模式下,甚至可以测得每秒 132000 个连接的会话速率,但这并不是很有用。
 .
.
第二个测试则是将请求转发到一个真实的服务器,并获取一个 64 字节的对象。
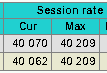
这些改进得益于能够在会话的关键阶段告知系统合并一些精心选择的 TCP 数据包。这导致了每个会话的数据包数量减少,从而节省了带宽和 CPU 周期。现在最小的会话在每一侧都减少到了 5-6 个数据包,而最初是 9 个。
2009/04/18 - 使用 Myricom 的 10GbE 网卡 (Myri-10G PCI-Express) 对 HAProxy 进行新的 10 Gbps 基准测试
引言
- 整整一年前,我对 Myricom 捐赠给我的高性能 10GbE 网卡进行了一些测试。一年来,HAProxy 已经有了相当大的发展。I/O 子系统被完全重构,现在可以利用 Linux 2.6 中实现的 TCP splicing 技术来避免在用户空间复制数据。本次测试将展示 TCP splicing 现在的可能性。
实验室设置
- 实验室几乎没有变化。两台 AMD 系统中的一台升级到了运行在 3 GHz 的 Phenom X4,但仅此而已。HAProxy 仍将运行在 2.66 GHz 的 Intel Core2Duo E8200 上。内核更新到了 2.6.27-wt5,这是 2.6.27.19 版本加上一些我需要的补丁,以便能轻松地从网络启动这些机器。2.6.27 内核包含了对 TCP splicing 的支持,对通用的大量接收卸载 (LRO) 的支持,还包括一个更新的 myri10ge 驱动程序,现在在 AMD 主板上双向传输 10 Gbps 流量已毫无问题。该内核修复了几个月前在准备这次测试时发现的 splicing 代码中的错误。看来并不是每个人都足够幸运能在这类出色的硬件上进行测试,因此在这种配置下出现错误是在所难免的 ;-)
硬件/软件配置
| 机器 | 角色 | 主板 | CPU | 内核 | myri 驱动 | myri 固件 | 软件 |
|---|---|---|---|---|---|---|---|
| AMD2 | 客户端 | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | inject31 | ||
| C2D | 代理 | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | haproxy-1.3.17-12 | ||
| AMD1 | 服务器 | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | httpterm 1.3.0 |
测试非常简单。一个 HTTP 请求生成器运行在更快的 Phenom (amd2) 上,因为这个软件是整个测试链中最耗费资源的。HAProxy 运行在 Core2Duo (c2d) 上。Web 服务器运行在较小的 Athlon (amd1) 上。连接是点对点的,因为我仍然没有 10GbE 交换机(接受捐赠 ;-))。HAProxy 配置为在响应路径中使用内核 splicing。
listen http-splice bind :8000 option splice-response server srv1 1.0.0.2:80
这里是一张机器连接在一起的照片。
{kind=link}
测试方法
- 一个脚本调用请求生成器,测试对象大小从 64 字节到 10 MB 不等。请求生成器持续连接到 HAProxy,以 500 到 1000 个并发连接的方式循环从服务器获取选定的对象,持续 1 分钟。每秒收集一次统计数据,因此我们有 60 个测量值。我们随意剔除了 5 个最好的值,因为它们可能包含一些噪声。接下来的 20 个最好的值被平均,并用作测试结果。这意味着剩下的 35 个值没有被使用。这不是问题,因为它们包含了在测试启动/结束阶段收集的值。实践表明,使用 20 到 40 个值会报告相同的结果。请注意,网络带宽是在 HTTP 层面测量的,不包括 TCP 确认包和 TCP 头部。在网络层面进行的其他抓包显示吞吐量略高。
- 收集到的值随后传递给另一个脚本,该脚本生成一个 GNUPLOT 脚本,运行后会生成一张 PNG 图表。图表中,绿色表示每秒的点击次数,这也恰好是连接速率,因为 HAProxy 每个连接只进行一次点击。红色表示每种对象大小所达到的数据速率(仅含 HTTP 头部和数据)。通常,对象越大,连接开销越小,带宽越高。
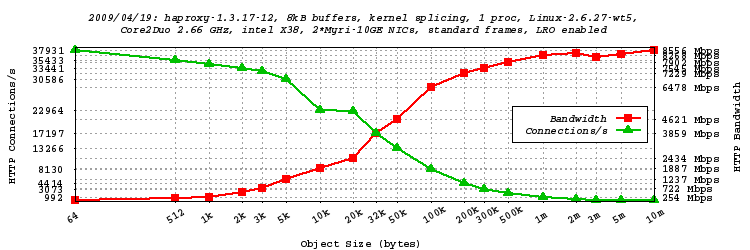
单进程模式、8kB 缓冲区、TCP splicing、启用 LRO、巨型帧测试
- 在此测试中,我们将 HAProxy 配置为使用内核的 splicing 功能,直接将 HTTP 响应从服务器转发到客户端,而无需复制数据。网络接口的 MTU 默认为巨型帧(9000 字节)。这些网卡也默认启用了大量接收卸载 (LRO),这使得可以一次性处理更大的数据段。两个网络中断都发送到 CPU 核心 1,而 HAProxy 单独运行在 CPU 核心 0 上。这是我迄今为止实现最高吞吐量的方式。总共测试了从 64 字节到 10 MB 的 19 种对象大小。

- 我们可以看到,现在即使只有一个 HAProxy 进程,也能毫无问题地达到 10 Gbps。网络测量显示,在客户端接口上,对于所有大于 1 MB 的对象,转发的流量达到了 9.950 Gbps,这在早期的版本中,如果不借助基于内核的 TCP splicing 是完全不可能实现的。此外,会话速率也大幅增加,测试期间在统计页面上看到的峰值达到了每秒 38628 个会话。这比一年前在相同硬件上的性能提升了 55%!可以注意到,对于大约 4kB 以上的对象,速率就达到了千兆,这比使用更常见的千兆网卡所观察到的情况要好得多。
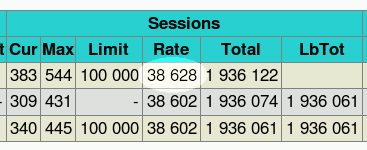
自从引入 LRO 和 TCP splicing 以来,CPU 使用率大幅下降。转发 9.95 Gbps 的以太网流量消耗的 CPU 不到 20%。
root@c2d:tmp# vmstat 1 procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 1 0 0 0 1951376 3820 19868 0 0 0 0 25729 23965 1 15 84 0 0 0 0 1950652 3820 19868 0 0 0 0 25744 23818 3 17 80 0 0 0 0 1950632 3820 19868 0 0 0 0 25720 24652 1 18 80 0 0 0 0 1949512 3820 19868 0 0 0 0 25531 24047 3 16 81 1 0 0 0 1948484 3820 19868 0 0 0 0 25911 22706 2 19 79 0 0 0 0 1949388 3820 19868 0 0 0 0 26189 23757 3 15 82 1 0 0 0 1948460 3820 19868 0 0 0 0 25811 23766 1 20 79
单进程模式、8kB 缓冲区、TCP splicing、启用 LRO、标准帧测试
- 大多数人无法在客户端启用巨型帧,因为他们连接到互联网,而互联网对巨型帧并不友好。然而,由于 HAProxy 是一个代理,它可以被用作巨型帧转换器,为内部网络保留巨型帧,而外部网络则以 1500 字节的 MTU 运行。本次测试是在客户端网络上以 MTU=1500 进行的。
关于 CPU 使用率,在满负荷(9.2 Gbps,1500 字节帧)下,CPU 使用率极低:用户态 2%,系统态 15%。这意味着 Myri-10G 网卡的 LRO 功能在为系统卸载方面效率极高。
root@c2d:tmp# vmstat 1 procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 0 0 0 0 1811764 3820 19844 0 0 0 0 26289 19089 2 14 84 0 0 0 0 1787924 3820 19844 0 0 0 0 26268 19578 1 13 86 1 0 0 0 1772704 3820 19844 0 0 0 0 26288 18517 3 13 84 0 0 0 0 1774260 3820 19848 0 0 0 0 26284 19522 2 15 83 1 0 0 0 1766144 3820 19848 0 0 0 0 26260 19042 3 15 83 1 0 0 0 1734412 3820 19848 0 0 0 0 26270 18603 4 15 81 0 0 0 0 1719864 3820 19848 0 0 0 0 26294 18886 1 14 85
会话建立/拆除速率
- 看看 HAProxy 在各种模式下支持多少会话建立/拆除是很有趣的。这对于想要防范攻击或支持极端负载的人来说很重要。第一个测试是模拟一个在 TCP 检查阶段阻止请求的 ACL。
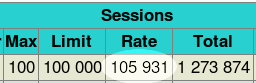
acl blacklist src 1.0.0.0/8 tcp-request content reject if blacklist请注意,此过滤器在 HTTP 请求解析之前应用。嗯,结果超出了我的预期,我不得不使用两台 AMD 系统来攻击 HAProxy 以获得分数,但我无法使 CPU 饱和,其使用率仍低于 75%。会话速率突破了每秒 10 万次的象征性大关,达到了每秒 105931 个会话!
HTTP 会话速率
许多其他人对客户端的 HTTP 会话速率感兴趣。与之前的测试不同的是,我们必须在做出决定之前完全解析 HTTP 请求。在某些情况下,客户端请求在被解析后可能不会被路由到服务器。当请求无效、被 ACL 阻止或重定向到外部服务器时,就会发生这种情况。因此,为了使测试最具真实使用场景的代表性,配置被设置为当 ACL 检测到本地服务器因维护而关闭时执行重定向。
acl service_down nbsrv -lt 2 redirect prefix http://backup.site if service_down会话速率仍然非常高:每秒 82702 个 HTTP 请求,同时还剩余约 20% 的 CPU 可用(例如用于日志记录)。
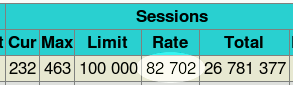
这里真正有趣的是,用户态 CPU 使用率在 23% 到 30% 之间波动,这意味着 HTTP 解析器处理 82700 个请求/秒所用的 CPU 不到核心的三分之一。由此推断,当支持 keep-alive 时,潜在处理能力约为每秒 25-30 万个 HTTP 请求。当然,这还没有考虑网络流量带来的额外工作量。
结论
- 这三次测试的第一个结论是,Linux 2.6 内核、Myri10GE 驱动和 HAProxy 自去年的测试以来都有了很大的改进。现在,可以用单个进程在 10GbE 线上全速运行,而不会消耗太多 CPU 资源,无论是否使用巨型帧,这都是一个好消息。10GbE 正在变得成熟。对各种网卡的一些测试倾向于表明,内核 splicing 并非总是可取的,尤其是在普通的网卡上。但那些精心设计的网卡确实能从这个特性中受益。Myri-10G 网卡无疑是其中之一。Linux 网络维护者 David Miller 表示,Sun 的 Neptune 芯片是另一个出色的选择。不过我还没有机会尝试。无论如何,对于任何认真考虑在单台机器上切换到 10GbE 速度的人,我只推荐这类设计精良的网卡。要充分利用 10GbE 仍然需要大对象(平均至少 1MB)。这与文件共享或在线视频完全兼容。对于混合流量的用户来说,以平均约 30 kB 的文件大小达到 3-4 Gbps 的目标会更现实一些(这仍然是每秒 15000-20000 个会话)。
HAProxy 的另一个很好的特性是它能作为 10GbE 网络的 MTU 转换器。Alteon 在 10 年前就做了这件事,以允许 1500 和 9000 字节的 MTU 在千兆网络上共存。现在,10GbE 也面临同样的问题。一些服务器将被设置为使用巨型帧,但外部网络不支持它们。在两个接口之间以完全透明模式设置 HAProxy 会有很大帮助。请注意,同样的情况也可能适用于以全线速进行 IPv6/IPv4 转换。
联系方式
如有任何问题或意见,请随时通过以下方式与我联系: