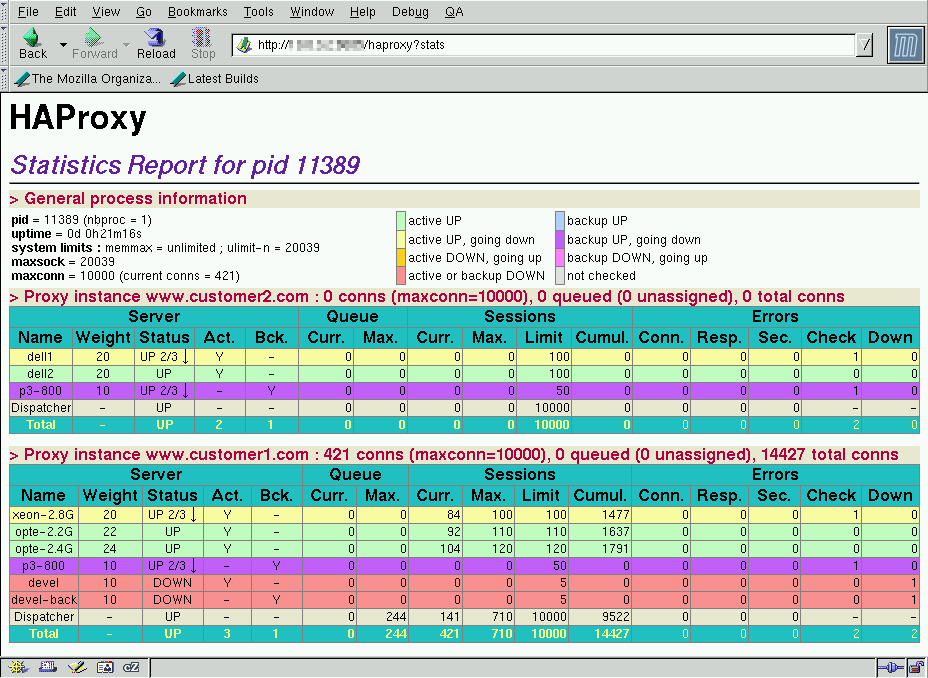
快速链接
最新消息描述
设计选择
支持的平台
性能
可靠性
安全性
下载
文档
在线演示
商业支持
使用 HAProxy 的产品
贡献
其他解决方案
联系方式
邮件列表归档
Willy TARREAU
使用 Myricom 的 PCI-Express 10G 网卡(Myri-10G PCI-Express)进行基准测试
...或者说如何用 HAProxy 实现 10G 负载均衡!实验室设置
- 我们将 4 块高性能网卡安装在 3 台机器上。为了能够对芯片组性能进行充分的实验,我选择了以下主板:
- ASUS M3A32MVP Deluxe + AMD Athlon64-X2/3.2 GHz 用于流量生成 (*2)
- ASUS P5E + Intel C2D E8200/2.66 GHz 用于托管 HAProxy
选择 P5E 的原因在于它搭载了速度极快的 Intel X38 芯片组,我另一台电脑也在用它。根据之前的测试,我*知道*它的速度足以支持 10 Gbps 全双工传输。
嗯,我选择两款不同的主板是正确的。基于 AMD 的主板无法向网络推送超过 8-9 Gbps 的流量,但接收没有问题。因此,部分测试使用我的台式机(也是 X38 芯片组)作为 HTTP 服务器,这样整个链路就不会被限制在 10 Gbps。
我还可以验证,当同时受到两台 AMD 机器的攻击时,这款出色的 Intel X38 芯片组可以毫无问题地向网络推送 20 Gbps 的流量。
不管怎样,无论进行何种测试,客户端总是直接连接到 HAProxy,HAProxy 本身又直接连接到服务器。这些都只是点对点连接,因为我没有 10G 交换机。
测试方法
- 测试非常简单。一个 HTTP 请求生成器在第一台 Athlon (amd1) 上运行。HAProxy 在 Core2Duo (c2d) 上运行。基于 TUX 内核的 Web 服务器在另一台机器上运行(amd2或我的电脑)。一个脚本调用请求生成器,测试从 64 字节到 100 MB 的对象大小。请求生成器在 1 分钟内持续循环连接 HAProxy,从 TUX 获取选定的对象。每秒收集一次统计数据,因此我们有 60 个测量值。我们主观地排除了 5 个最佳值,因为它们可能包含一些噪音。接下来的 20 个最佳值被平均后作为测试结果。这意味着剩下的 35 个值没有被使用。这不是问题,因为它们包含了在性能爬升/下降期间收集的值。实际上,测试表明,使用 20 到 40 个值报告的结果是相同的。
- 收集到的值随后传递给另一个脚本,该脚本生成一个 GNUPLOT 脚本,运行后会生成一张 PNG 图表。图表中,绿色部分显示每秒的点击数,这也恰好是连接速率,因为 HAProxy 每个连接只进行一次点击。红色部分显示了针对每个对象大小所达到的数据速率(仅 HTTP 头+数据)。通常,对象越大,连接开销越小,带宽越高。
单进程模式测试,16kB 缓冲区
- 这第一个测试是“默认”测试。它是一个标准的 HAProxy 运行在 C2D 上。客户端是amd1,服务器是运行在我电脑(X38)上的 TUX,代理运行在C2D上,同样使用 X38。测试迭代了从 64 字节到 100 MB 的 20 种对象大小。
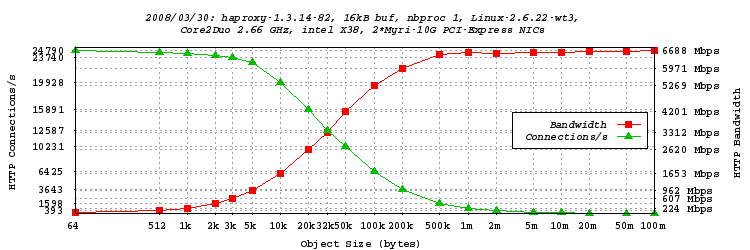
- 我们看到,仅用一个进程,我们无法超过 6.688 Gbps 的转发 HTTP 流量。使用 32 kB 的对象时达到了这个值的一半。大约 6 kB 的对象可以达到 1 Gbps。使用 50kB 的对象时已达到 4 Gbps(超过 10000 连接/秒)。峰值连接速率为 24790 连接/秒,这已经相当不错了。
双进程模式测试,16kB 缓冲区
- 由于 C2D 有 2 个核心,看看机器在 2 个进程下的表现会很有趣。参数nbproc被设置为 2,而tune.maxaccept仅设置为 1,以确保请求能够均匀地分布在两个核心上。两个网络中断(218 和 219)被分配到不同的 CPU 核心,以避免缓存行抖动,因为 C2D 没有像 Athlon 那样的统一缓存。客户端仍然是amd1,服务器仍然是运行在我电脑(X38)上的 TUX。测试与前一个完全相同。
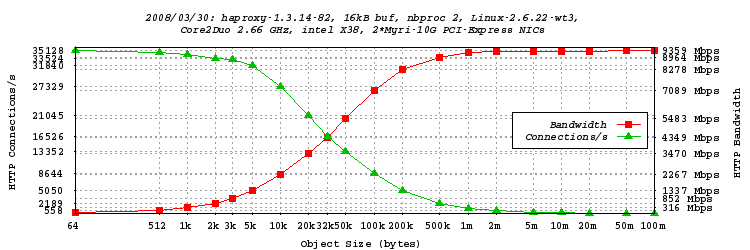
- 我们看到,这次使用两个进程,我们达到了 9.359 Gbps。这非常接近线速。这些 Myri-10G 网卡真是太棒了!系统每秒大约执行 73000 次全缓冲读取和 73000 次全缓冲写入,因此缓冲区大小在这里有显著影响。因此,另一组测试将使用 >60 kB 的缓冲区进行。我们还注意到,与单进程相比,使用更小的对象就能达到更高的速率。32 kB 的对象已经超过 4 Gbps,而大约 4kB 的对象就已经超过 1 Gbps。同样值得注意的是,连接速率达到了 35128 次点击/秒!又打破了一项记录!
双进程模式测试,63kB 缓冲区
- 如上所述,我们正在处理非常高的读/写速率,因此扩大缓冲区可能是值得的。由于网卡默认使用巨型帧(9kB),我将缓冲区大小设置为 63 kB(7 个帧)。好吧,为了适应 MSS,它本应是 62720 字节,但这并不是一个真正的问题……
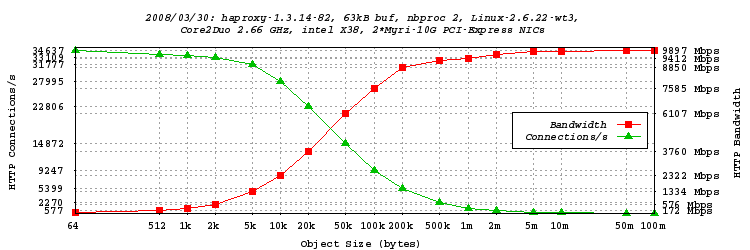
- 性能更好了,创下了 9.897 Gbps 的 HTTP 流量新纪录! 现在对于 50kB 的对象,我们已经超过了 6 Gbps。不幸的是,有些值没有被测试到,所以这个测试很快会重新运行。我们还注意到,绝对最大连接速率比使用较小缓冲区时略低。这很可能是由于较大缓冲区导致缓存抖动更严重。
初步结论
- 这些网卡的工作效果惊人地好。甚至比我想象的还要好。此外,虽然它们没有创造什么奇迹,但它们给系统带来的压力非常小(我怀疑驱动程序的质量非常出色)。在使用 TUX 达到 20 Gbps 时,CPU 空闲率高达 85%! 我还注意到,仅仅通过 10G 网卡而不是 1G 网卡进行路由(当时线路远未饱和),连接速率就从 55000 次点击/秒跃升至 68000 次点击/秒。
- 可惜的是,基于 AMD 的主板无法向网络推送足够的数据。我怀疑 AMD790FX 芯片组根本就有问题。事实上,如果我超频 PCI-E 总线,我得到的额外带宽比例是完全相同的。不幸的是,系统在超过 12% 的超频后就不稳定了,这还不足以使线路饱和。这是一个 PCI-E 2.0 总线,我尝试了很多参数设置都没有成功。此外,如果将网卡插入到两个蓝色的 PCI-E 插槽(1 和 3)中,它就无法被检测到。我还注意到,在全双工操作时,主板的输入+输出总流量在 12 Gbps 左右就饱和了。如果我需要再买新主板,现在我肯定只会选择 P5E。至少我通过实验得到了验证。
- 接下来的研究方向将集中在动态缓冲区分配,以及对 MTU 的实验。现在 MTU 是 9000,我注意到在 1500 时比特率减半。但是,能用这么便宜的机器处理 1500 MTU 下的 5 Gbps 流量已经非常出色了!
联系方式
如有任何问题或意见,请随时通过以下方式与我联系